

Generative AI for Clinical Trial Matching
Large Language Models have the potential to revolutionize clinical trial matching.


Clinical trials are the primary mechanism for advancing new medicines. However, recruiting patients to clinical trials is a critical bottleneck. A recent report estimates that 86% of trials do not meet their enrollment timelines, and 30% of Phase 3 trials fail because they cannot recruit enough patients.
Could Large Language Models or LLMs help solve this problem? If so, we could leverage AI to expedite trial enrollments and accelerate new therapeutic interventions.
Introduction to Trial Matching
To target specific disease conditions, each clinical trial is defined with a detailed list of eligibility criteria. For example, a clinical trial may only be open to patients with a specific cancer subtype and a specific genomic alteration.
Clinical trial matching is the process of comparing a patient’s medical record to the eligibility criteria associated with a clinical trial. The process is overseen by clinical staff, and usually involves multiple stages of pre-screening and discussion with the patient, the patient’s primary physician and clinical trial staff.
There are multiple options for automating specific steps in the trial matching process, and multiple academic groups and companies have developed richly featured computational solutions.
For example, at Dana-Farber, we have developed MatchMiner, an open-source clinical trial matching platform. The system is designed to match patients to biomarker driven clinical trials, and we use structured genomic data and manually curated clinical trials to determine matches. Other cancer centers have similar systems. For example, Memorial Sloan Kettering has developed a platform named DARWIN, and MD Anderson has developed a platform named OCTANE or Oncology Clinical Trial Annotation Engine.
Multiple commercial matching systems have also been developed. This includes: Antidote, Deep6.ai, GenomOncology, Mendel.ai, and IBM Watson. Multiple sequencing companies also offer trial matching solutions, including Foundation Medicine, Caris Life Sciences and Tempus.
The Challenge: Unstructured Text
Despite the promise of these platforms, they all suffer from a central challenge: comprehending complex medical information written in unstructured human language. This medical information is embedded within clinical trial protocol documents and within patient medical records.
More specifically, critical trials are defined by a complex set of inclusion and exclusion criteria, usually written in medical terminology. To see how complicated these criteria can get, check out just one example of a Phase 1, 2 trial targeting patients with a specific TP53 mutation:
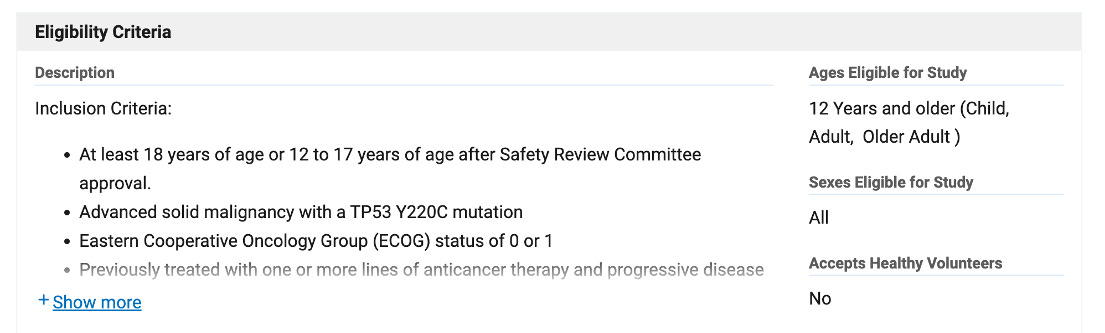
The trial eligibility for this one trial spans 1.5 pages, and covers genomic biomarkers, prior treatments, cancer types, and other medical conditions.
Multiple academic and commercial groups currently invest considerable human resources in parsing eligibility criteria and converting unstructured text to structured computational criteria for trial matching. For example, at Dana-Farber, we have a small team of curators that read protocol documents and translate trial criteria into a standardized computational format that we call Clinical Trial Markup Language (CTML). We have now curated approximately 600 precision cancer medicine trials, and manually review all trials every quarter.
Trial criteria is only one part of the problem though. Far more challenging is the crucial medical information encoded in clinical notes and embedded within Electronic Medical Record (EMR) systems. For example, each time an oncologist meets a patient, he or she will write up a clinical note summarizing the visit. The note may indicate the stage of disease, new evidence of disease progression, or a change in treatment. Studies estimate that 70-80% of patient information resides in these unstructured clinical notes.
At most cancer centers, clinical research coordinators and nurses will review unstructured data within the EMR to determine clinical trial eligibility. However, this is time-consuming work. One study found that it can take clinical staff an average of 1 hour to review one patient for a single Phase III clinical trial. Some outlier cases can take up to 4-6 hours.
These challenges are not new. Prior work in clinical trial matching has focused on using Natural Language Processing (NLP) techniques to parse eligibility criteria and clinical notes. These systems have used traditional NLP techniques, such as named-entity recognition (NER), negation detection, logic detection and rule-based processing to semantically parse medical information. For example, the open source Criteria2Query tool leverages multiple NLP techniques to parse and structure clinical trial eligibility criteria.
Large Language Models
Large Language Models are new AI tools trained on massive examples of text and are exceptionally good at processing and understanding human language. It was therefore only a matter of time before research groups started to think about leveraging LLMs for clinical trial matching.
To understand the promise and peril of LLMs for trial matching, I want to start by setting the scene.
First, LLMs are incredibly flexible systems. Without any additional medical training data, existing LLMs can be adapted to a host of clinical scenarios. This is usually referred to as zero shot learning, where one prompts the LLM to reason about a novel scenario and output an answer. It can also refer to in context learning where the prompt includes a few specific examples with input and output, and we then ask the LLM to reason about a related, but new scenario.
Of course, this great flexibility comes at a cost. LLMs are not perfect. They can answer medical questions incorrectly. They can even hallucinate answers. This makes their use within healthcare particularly problematic.
Second, we are still in the early stages of using LLMs for clinical trial matching. However, two major approaches have now emerged.
This first approach is structure-then-match. In this approach, the LLM is prompted to extract structured eligibility criteria from clinical trials, and separately prompted to extract structured medical information from clinical notes. Downstream NLP modules are used to further standardized structured data to specific medical ontologies. Finally, rules-based logic is used to determine trial matches. This approach has the advantage of enabling trial matching on both structured and unstructured patient data. For example, clinical notes can be processed by the LLM, but structured genomic data and prior treatments can be extracted directly from the EMR, and both can be fed into the rules engine.
The second approach is end-to-end-matching. In this approach, the LLM is prompted with clinical trial eligibility criteria for a single trial and all clinical notes for a single patient, and the LLM is asked directly to determine whether the patient is a match. The LLM is also prompted to explain its clinical reasoning. This approach is direct and flexible, and the clinical reasoning provided by the LLM can be directly reviewed by clinical staff and integrated into existing pre-screening protocols.

There are already multiple preprints exploring both approaches. For brevity, I will focus on three recent studies.
First up is a preprint from Microsoft Research and Providence. The authors use the structure-then-match approach, and specifically focus on structuring disease histology and biomarker eligibility criteria. LLMs were tested on 53 clinical trials, and results were compared to expert curations by molecular pathologists. The results were promising, and LLMs were shown to clearly outperform existing NLP methods: “Out of box and with no more than three examples, cutting-edge LLMs, such as GPT-4, can already structure trial eligibility criteria with reasonable performance, outperforming strong baselines from prior systems.”
Next up is a pre-print from Stanford. The authors focus on end-to-end trial matching, and tested their setup against a small public data set of 288 diabetic patients, referred to as the n2c2 cohort and a single clinical trial with 13 inclusion criteria. The authors tested GPT-3.5, GPT-4 and the open-source LLaMA-2. As with the Microsoft paper, the authors found that LLMs clearly outperformed existing NLP methods: “We achieved state-of-the-art performance on the 2018 n2c2 cohort selection challenge, achieving gains of +6 Macro-F1 and +2 Micro-F1 points over the prior best model without any feature engineering.” Importantly, the authors also assessed the overall cost of trial matching and offer multiple solutions for reducing costs.
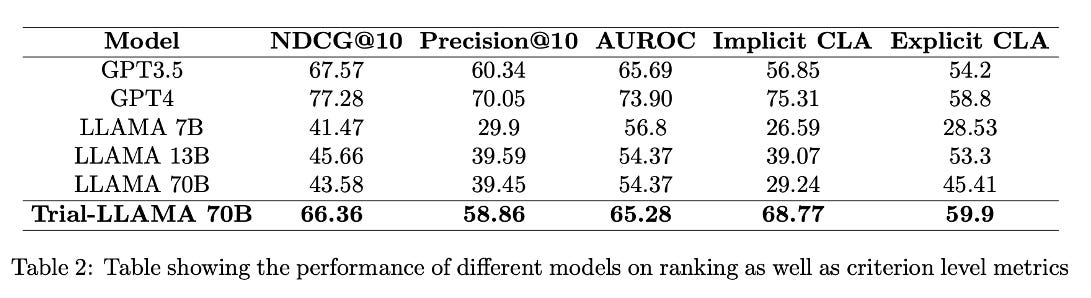
Finally, the company Triomics has published a pre-print describing an open source Trial-LLaMA. The authors make a solid case that open source LLMs are needed for trial matching to reduce cost, ensure patient privacy, and address reproducibility concerns with closed, proprietary models. The authors compared trial matching performance in GPT-3, GPT-4 and LLaMA. Using the base model, LLaMA under-performed both GPT-3 and GPT-4. However, the authors then used the output from GPT-4 to fine-tune LLaMA and saw significant improvements. Results are summarized below.
Challenges Ahead
These three studies hint at larger challenges ahead and provide a roadmap for future work.
First, there are very few patient data sets for benchmarking. Clinical notes contain Protected Health Information (PHI), and while there are mechanisms to de-identify clinical notes, there is no current method that can automatically detect and mask 100% of all PHI. For example, the company John Snow Labs has spent considerable effort in de-identifying clinical notes and now reports that it is able to remove 99.1% of PHI from clinical notes.
This is impressive. But, for risk averse hospitals that must adhere to HIPAA, 99.1% is just not good enough, and PHI leakage seriously risks patient privacy. Public data sets for trial matching on clinical notes are therefore likely to remain extremely rare. Furthermore, in the absence of public reference data sets, most groups will be left to mine their own institutional data sets. Institutions may also fine-tune LLM models with patient notes, but such models can also leak PHI. This will severely limit the generalizability of any findings and limit the sharing of fine-tuned models.
Second, LLMs will require clinical oversight. If clinicians blindly rely on imperfect LLMs for medical decisions, they are likely putting patients at risk. Furthermore, hospitals that rely on imperfect LLMs for medical decisions are likely to be liable for AI-generated mistakes.
Because of the high stakes involved, I seriously doubt that any LLM will make autonomous trial matching decisions anytime soon.
More likely, LLMs will be used to pre-screen patients, but clinical staff will be required to review all results and make the final call. This will require the development of robust
“human in the loop” workflows, where clinical research coordinators, nurses, and oncologists will be required to review all results.
Third, trial matching is only one factor that impacts patient enrollment to clinical trials. Many other factors – medical, social, and economic – may have a bigger impact on enrollment rates. For example, multiple financial barriers to trial participation exist, including geographic proximity, transportation costs, childcare costs, and work flexibility. It is therefore no surprise that overall income remains one of the strongest predictors of clinical trial participation.
Where you are treated can also have a big impact. According to one recent study, ~6% of patients with cancer enroll in clinical trials, but for those patients fortunate enough to be treated at an NCI designated comprehensive cancer center, participation rate is closer to 19%. For patients treated at community cancer programs, clinical trial options remain limited, and participation rate is closer to 4%. Furthermore, if new advanced LLM matching programs are concentrated within NCI designated cancer centers, AI enablement is likely to further exacerbate already existing inequities.
Overcoming these challenges will require considerable effort, investment, and experimentation.
As aways, let me know your thoughts in the comments below.
Special thanks to Dr. Kenneth Kehl from Dana-Farber Cancer Institute, for providing feedback on an earlier draft of this post.
Ethan, this is great work! Did you publish this in a journal? If not, I’d love to publish this as front matter for my peer-reviewed journal AI in Precision Oncology. I serve as Editor-in-Chief there and think this is a topic that needs more attention. Thanks for your work—I’m just getting started on Substack today, actually. love the promise of this forum.