


AI in Mammography: 2025 Clinical Trials Update
AI notches significant successes in two key clinical trials.

Two large-scale clinical trials using AI in mammography have reported significant results this year. Both demonstrate that AI can detect more cancers than human radiologists alone, while simultaneously reducing the workload of radiologists.
Both trials were run in Europe, the first in Germany, the second in Sweden. The first reported results in January of 2025, and is referred to as PRAIM (PRospective multicenter observational study of an integrated AI system with live Monitoring). The second reported results in March 2025, and is referred to as MASAI (Mammography Screening with Artificial Intelligence). I wrote about the first round of interim results from MASAI back in 2023. See Return to Malmö.
Before I review the results of each trial, it’s useful to first consider how complicated such trials can be.
First, most women screened for breast cancer are negative. To evaluate the impact of AI on mammography, we therefore need huge sample sizes. In the case of PRAIM, the trial screened 463K women. In the case of MASAI, the trial screened 106K women.
Second, there are a wide number of FDA and CE-certified AI tools in mammography to choose from. PRAIM went with a screening tool from the German-based Vara; MASAI went with Transpara screening tool from the Dutch-based Screenpoint Medical.
Having selected an AI tool, one next needs to consider how such a tool will be integrated into the screening workflow. In Europe, standard of care requires that two independent radiologists review every mammogram, and this formed the basis of the control arms for both PRAIM and MASAI.
The AI arms for each trial were significantly different though. In PRAIM, the AI intervention arm consisted of two radiologists, but at least one radiologist used the Vara AI system.
In MASAI, the AI intervention arm used a risk-stratified screening protocol. Specifically, the AI first screened the mammogram, and returned a risk score of 1-10. Risk scores 1-9 were sent to a single radiologist; risk scores of 10 were sent to two radiologists.
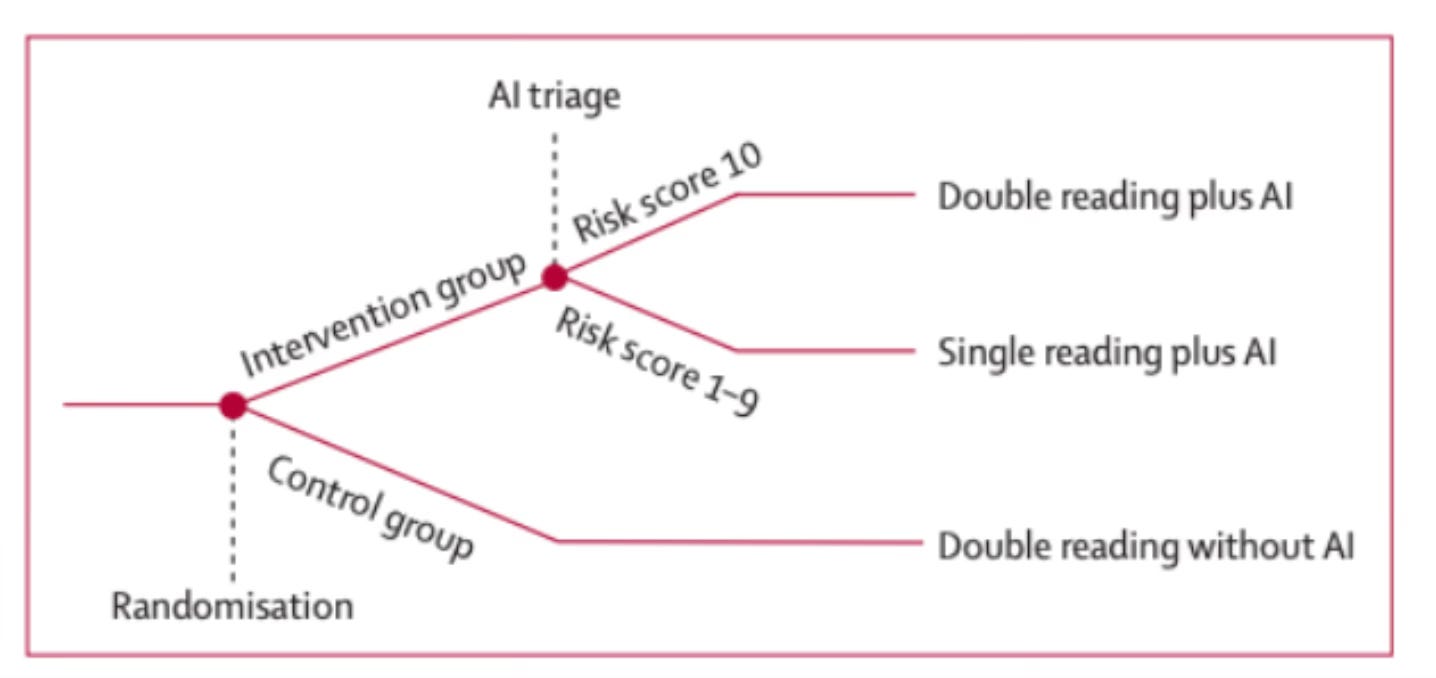
Figure 1: Overview of the MASAI Clinical Trial. Reprinted from Lång, K. et al. (2023).
Figure 2: Example screenshot of the Vara AI system, highlighting a suspicious region in the right panel. Reprinted from Eisemann et al. (2025).
Finally, one has to select exactly what to measure.
In mammography, a “recall” refers to a radiologist suspecting cancer in the mammogram, and calling that patient back for additional diagnostics. This may ultimately lead to a surgical sample or a core-needle biopsy, where a pathologist renders the gold standard verdict on presence of absence of cancer.
In both PRAIM and MASAI, the study teams measured the rate of recall across both arms, and of those patients recalled, how many were truly diagnosed with cancer, based on the pathological gold standard. Using pathology data, you can measure overall cancer detection rate; when you add in recall, you can also calculate the positive predictive rate, or the number of true positives found in all the recalled cases.
There are two important caveats to the measurements above.
First, it’s important to identify the type of cancer or pre-cancer identified. Most women are diagnosed with invasive breast cancer. But, a subset of women are diagnosed with ductal carcinoma in situ or DCIS, which is considered a form of pre-cancer. Depending on the nature of the pre-cancer, it may never evolve into full-blown cancer. A screening protocol that identifies more DCIS patients may therefore result in over-diagnosis and over-treatment. Both PRAIM and MASAI therefore also tracked the type of cancer detected.
Second, using pathology reports, we have gold standard data for all biopsied cases, but what about all the other cases?
There is no ethical or logistical method for obtaining biopsies for all women screened, and we therefore do not truly know the extent of cancer within a population sample.
To get around this issue, the next best option is to measure “interval cancers”. Interval cancers are those cancers that arise between mammograms, and are usually identified by physical symptoms. In theory, these interval cancers represent cancers missed by mammography. Reducing interval cancers are therefore seen as the ultimate test of whether a new screening test significantly improves on standard of practice. However, neither of the trials report on interval cancer rates. That is because women must be tracked for at least two years to accurately identify all interval cancers.
The MASAI trial estimates that this will be completed in the summer of 2025, and a third paper will be prepared.
With that setting, here are the results of the two trials.
First and most significantly, both the PRAIM and MASAI trials observed significantly higher rates of cancer detection using AI.
In PRAIM, the AI arm had a cancer detection rate of 6.7 per 1,000 cases, compared to 5.7 in the control arm. In MASAI, the AI arm had a cancer detection rate of 6.4 per 1000 cases, compared to 5.0 in the control arm. As noted above, these are true cancer cases diagnostically verified by pathologists.
These may sound like small increases, but given that most women are screened as negative, the percentage change is actually quite large. For example, in the MASAI trial, this translates to a 29% increase in cancer detection. Extrapolate that to an entire national screening program like Sweden’s, where over 1 million women are screened each year, and we are talking thousands of additional women that have breast cancer and would likely to be missed without AI. That’s huge.
The one caveat is that in both trials, the AI arms detected more pre-cancerous DCIS cases than the control arms. There are some real subtleties here though. As the study authors of MASAI write:
“Roughly half of the extra detected ductal carcinoma in situ were of nuclear grade III, which is considered clinically relevant early detection as the biological profile is more aggressive with a high likelihood of becoming invasive. Still, the other half were of intermediate risk and could therefore potentially add to overdiagnosis, but the numbers are small (nine more detected ductal carcinoma in situ grade II).”
Overall, both PRAIM and MASAI also hold up on recall rates.
At one extreme, you could simply increase your recall rate in the hopes of detecting more cancer cases, but this would result in many more women undergoing unnecessary diagnostic procedures. In PRAIM, the recall rate in the AI arm was 37.4 per 1,000 cases, and actually lower than the 38.3 per 1,000 cases observed in the control arm. In MASAI, the recall rate was slightly higher in the AI arm compared to the control arm, but was not statistically significant.
Both trials also point to significant efficiencies in using AI. The PRAIM trial did not directly compare workloads in the two arms, but estimates that the AI arm resulted in a 56.7% reduction in screen-reading workload. MASAI more directly measured the two arms, and reported a 44.2% reduction in the screen-reading workload.
The big takeaway is that in both trials, the AI intervention was able to detect more cancers, without a significant increase in unnecessary diagnostic procedures, and radiologists were able complete their work in significantly less time.